
Building Resilient Software: Ensuring Stability and Reliability!
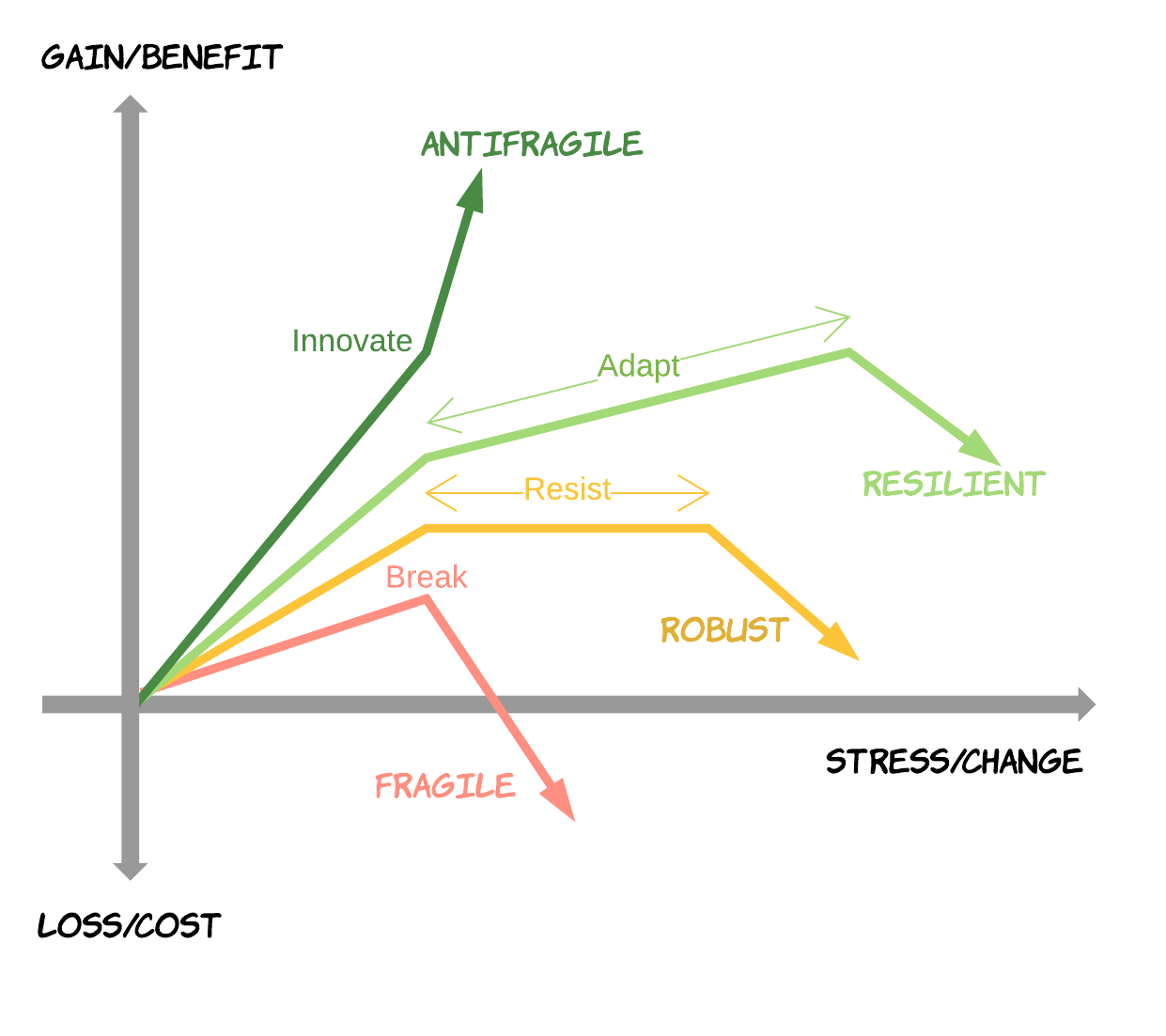
Building resilient systems is a crucial aspect of product development that focuses on ensuring software stability and reliability, even in the face of challenges and unexpected events.
Resiliency patterns play a significant role in achieving software reliability by providing strategies and techniques to make systems more robust and better equipped to handle various scenarios.
Importance of Resiliency
From my experience, I can confidently say that taking steps to minimize downtime doesn't just benefit your system performance, but it also contributes to a reliable user experience.
By proactively addressing potential issues and implementing strategies for faster recovery times, you can ensure that your users have a smooth and uninterrupted experience with your website or application.
This not only enhances customer satisfaction but also helps in improving the overall performance of your system.
So don't underestimate the importance of minimizing downtime - it's an investment well worth making!
Incorporating fault tolerance and performance optimization measures is crucial for enhancing resilience and ensuring a robust system that can withstand unexpected challenges while delivering top-notch performance for an exceptional user experience.
Challenges in Software Reliability
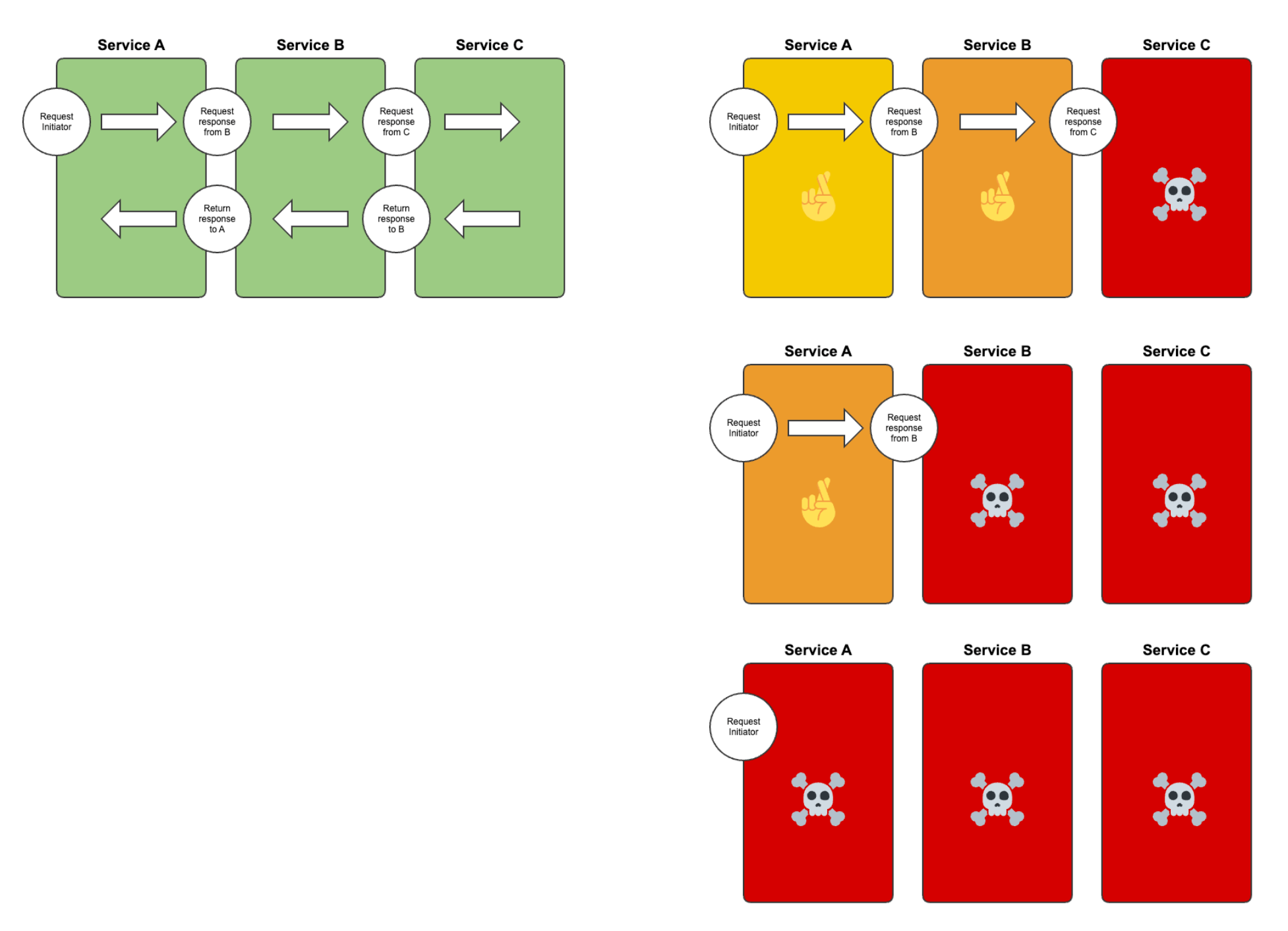
When it comes to building resilient systems, there are several common challenges that we need to address in order to ensure software stability. Let's take a look at some of these challenges:
- Failures and Errors: Unpredictable failures and errors that can lead to system crashes or unexpected behavior.
- Limited Resources: Finite system resources, such as CPU, memory, and network bandwidth, which can become overwhelmed by high demands.
- Network Issues: Problems like latency, timeouts, and network failures that disrupt communication and cause service disruptions.
- Service Degradation: Unavailable or underperforming services or dependencies that affect system functionality and user experience.
- Scalability and Load Handling: Difficulties in scaling systems to handle increased loads while maintaining performance due to bottlenecks and resource constraints.
- System Recovery: The need for systems to recover from failures efficiently and restore stability to minimize downtime.
- Distributed System Challenges: Maintaining consistency, handling partial failures, managing replication, and coordinating actions across multiple components in distributed systems.
System Reliability Techniques
To address these challenges and enhance the resilience of a system, one can make use of various resiliency patterns. There are several software resilience strategies that offer effective solutions.
Fallback Strategy for Service Resilience
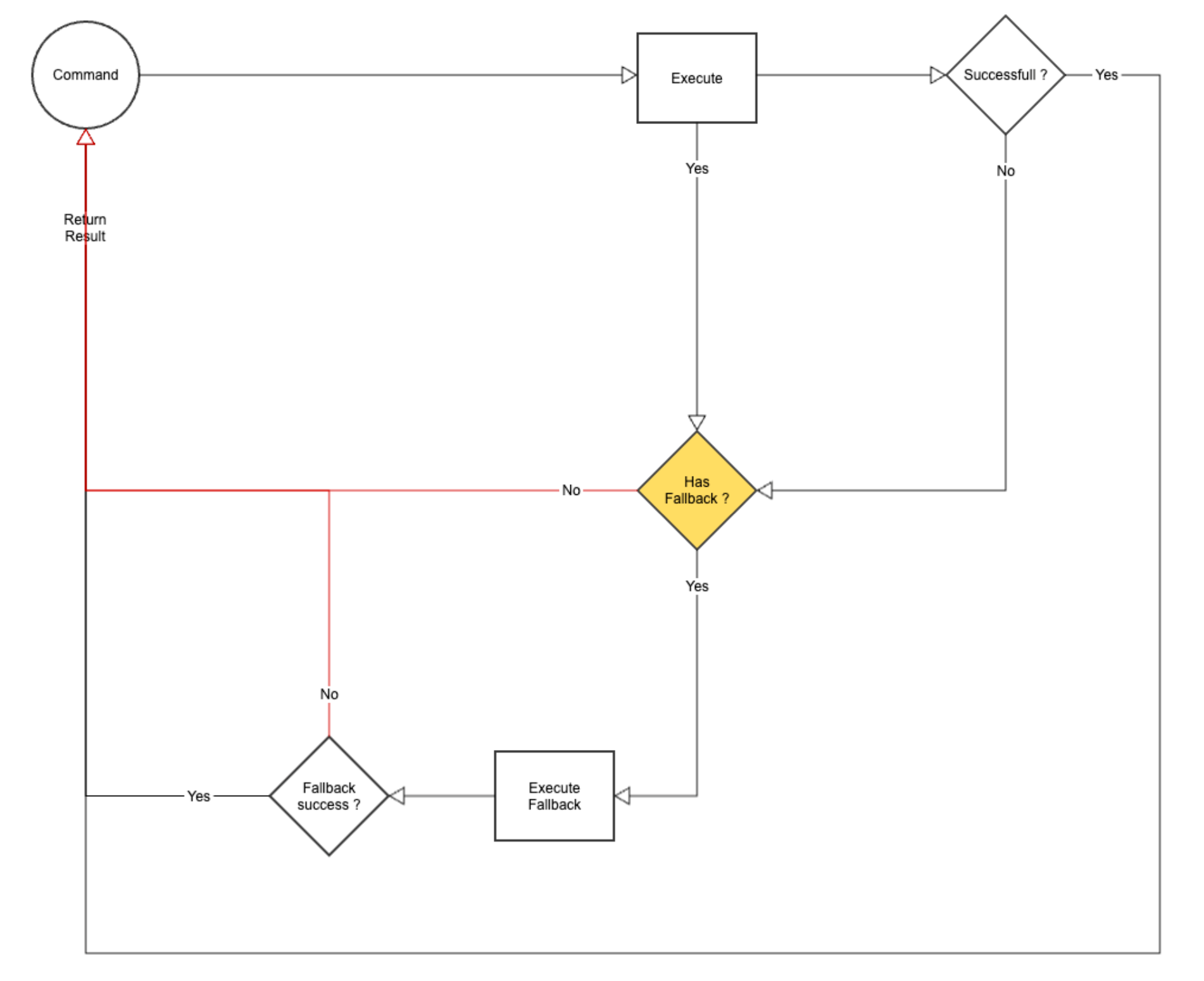
The Fallback pattern provides an alternative response or behavior when an error or failure occurs.
It allows you to define a fallback function or strategy that is executed when the primary operation fails.
This fallback can be used to provide a default value, return a cached result, or perform a simplified version of the operation.
Retry Patterns in Error Handling
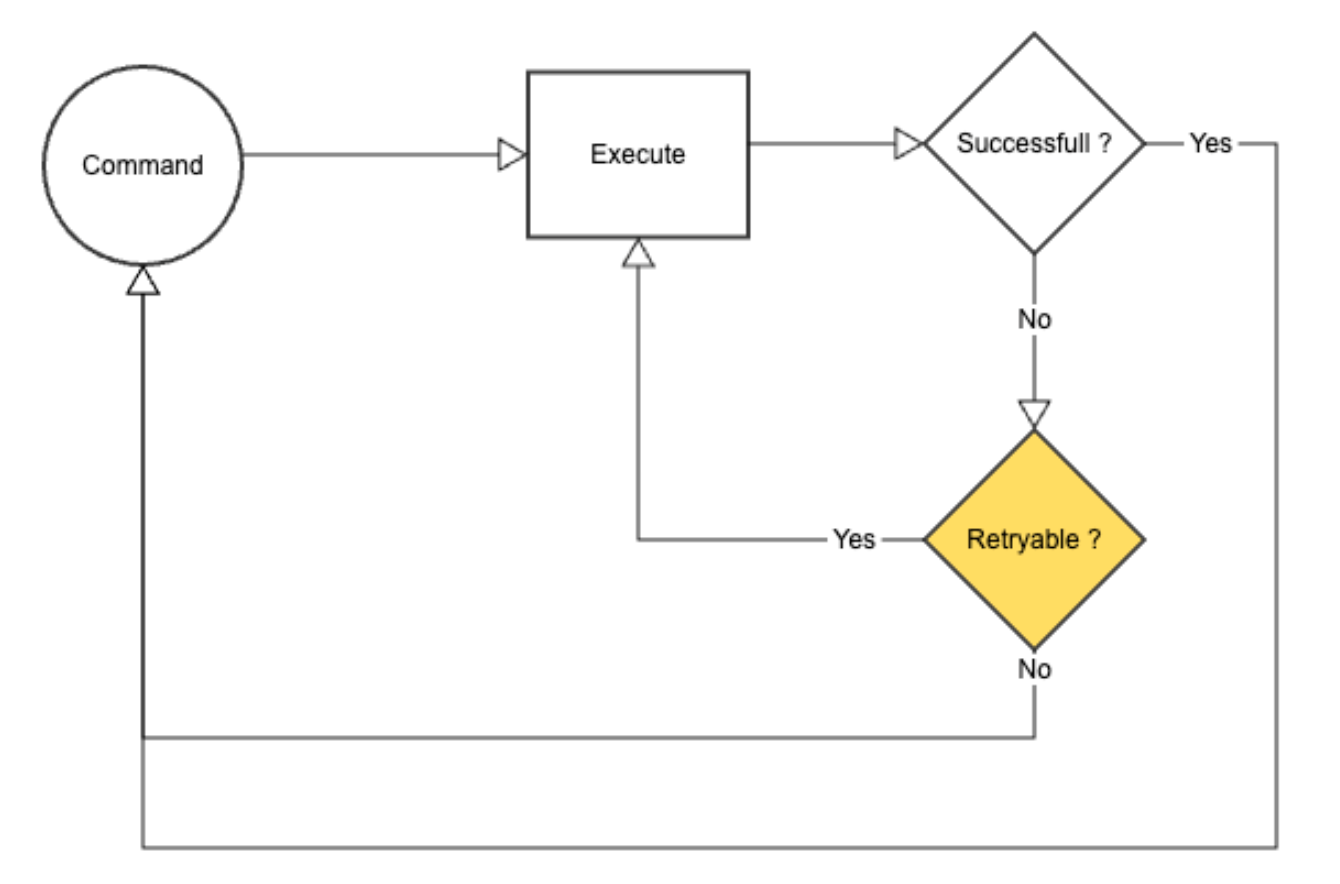
The Retry pattern allows for automatic reattempting of an operation or task that has previously failed.
It sets a maximum number of retry attempts and a delay between retries, helping to manage transient failures and recoverable errors by retrying the operation after a failure occurs.
Circuit Breaker in Fault Tolerance
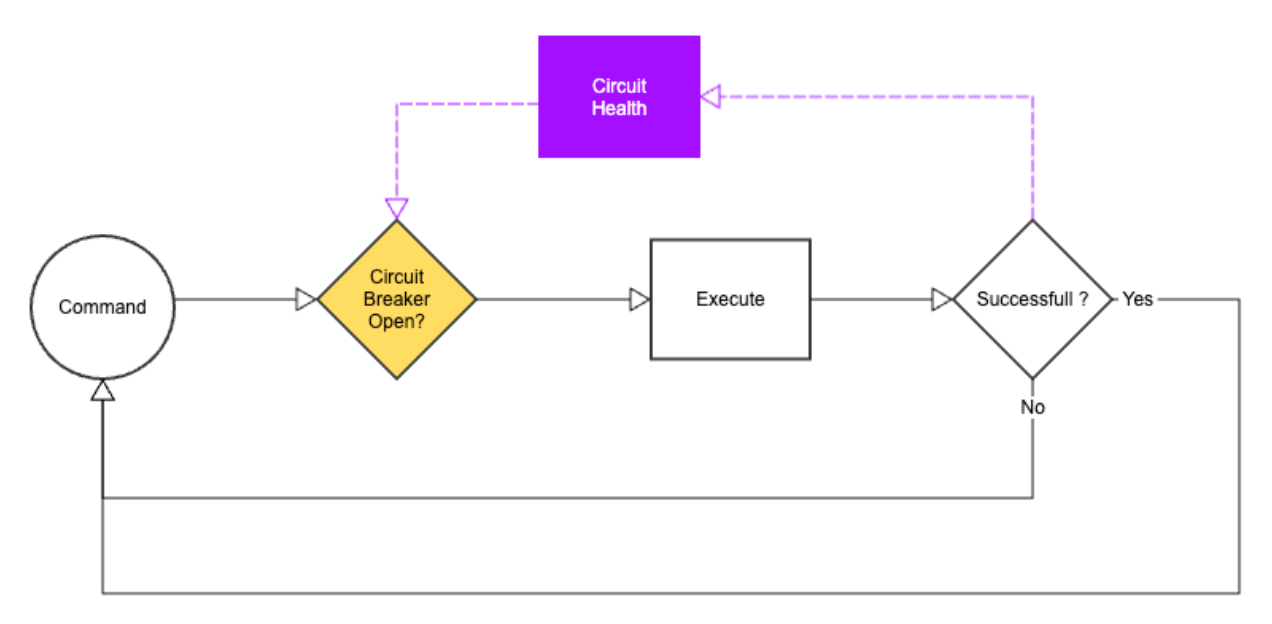
The Circuit Breaker pattern improves system resilience by monitoring the availability of a service or resource. It identifies failures and interrupts the circuit to stop additional requests from reaching the failing component.
This helps decrease the load on the failing component and reroutes requests to an alternative path or fallback mechanism. After a specified recovery timeout, the circuit can be closed again to enable request flow.
Timeout Pattern in Distributed Systems
The Timeout pattern ensures that the execution of a task is limited to a specified duration.
If the task exceeds the defined time limit, an exception is raised, or an alternative action is taken. It helps prevent excessive processing time and improves system responsiveness.
Bulkhead Pattern in Microservices Architecture
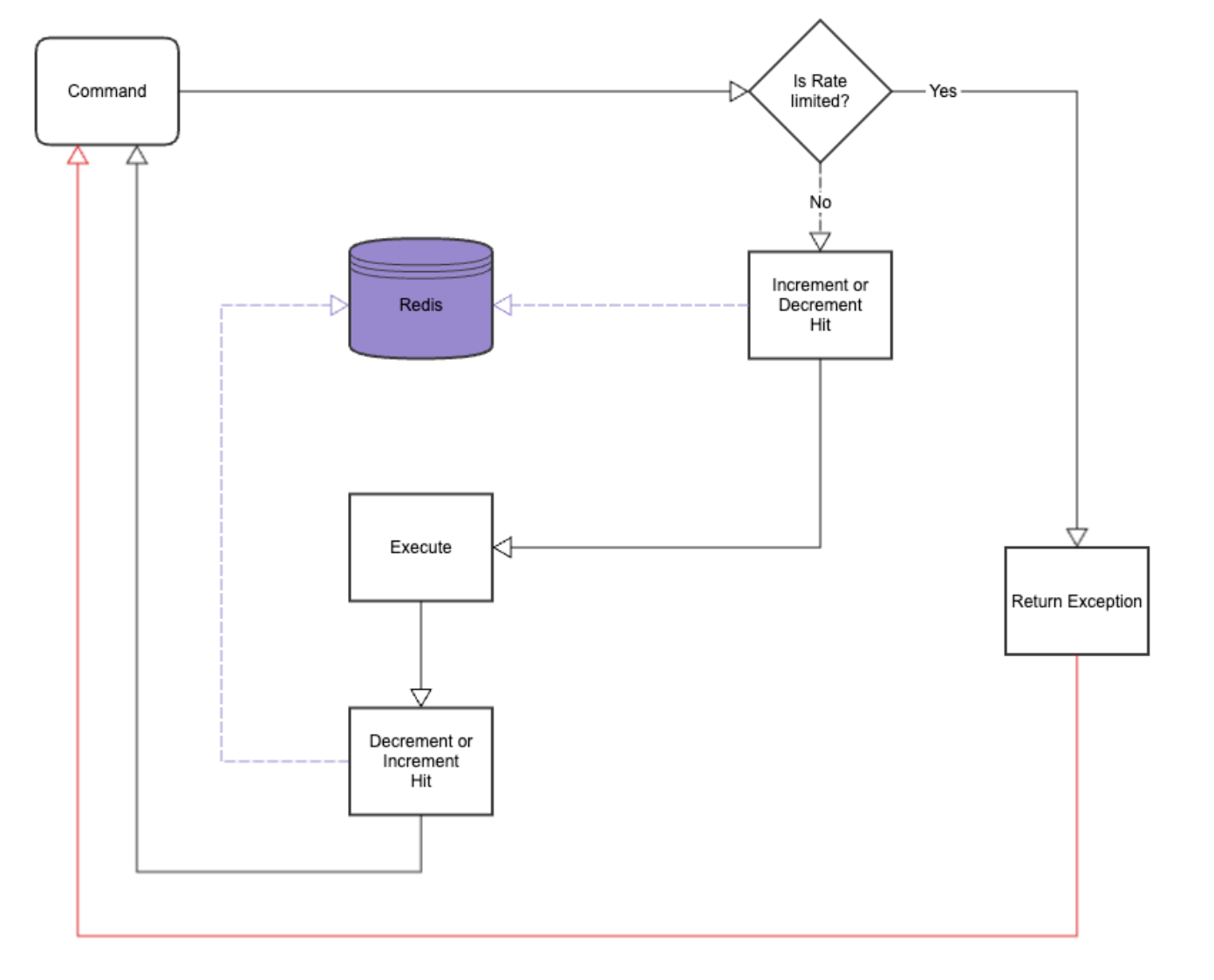
The Bulkhead pattern restricts concurrency and separates resources for various operations or components. It divides resources, such as threads or connections, into distinct pools to prevent one operation from overpowering the entire system.
This pattern offers fault isolation, ensuring that failures or resource depletion in one partition do not impact others, thereby enhancing overall system stability and performance.
Examples:
- Rate Limiting
- Kubernetes CPU / Memory Limit Semaphore
- Thread Pool
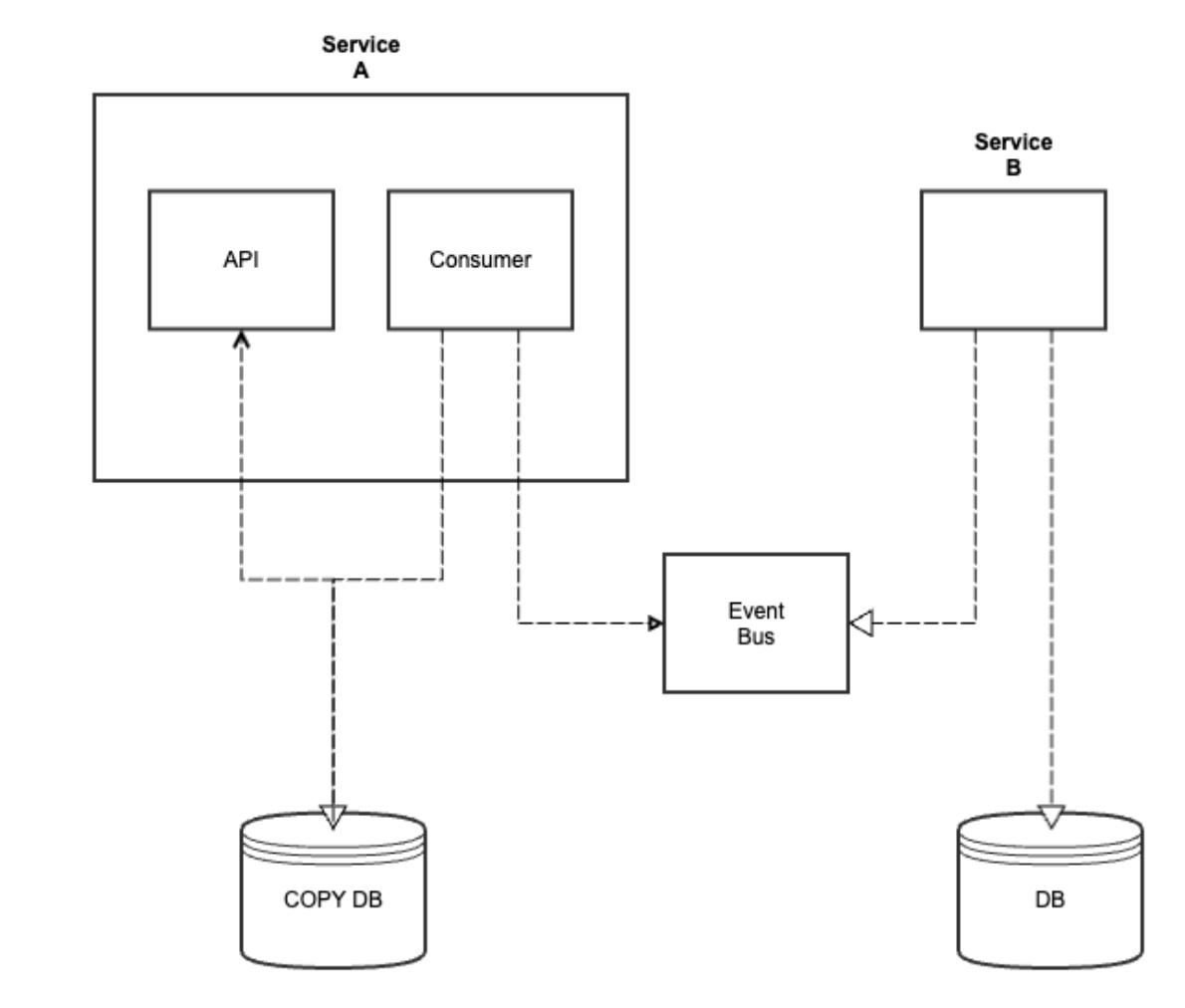
Replication Pattern for High Availability
The Replication pattern involves creating and maintaining multiple copies of data or services across different nodes or systems. It improves system reliability, availability, and performance by distributing the workload and providing redundancy.
Replication can be synchronous or asynchronous, depending on the need for consistency and performance.
When a request is made, it can be directed to any available replica, providing load balancing and fault tolerance.
Replication helps in achieving higher fault tolerance by ensuring that if one replica fails, others can continue to serve the requests. It also improves performance by distributing the workload across multiple replicas, reducing latency and increasing throughput.
However, managing consistency between replicas and handling conflicts during updates can be a challenge.
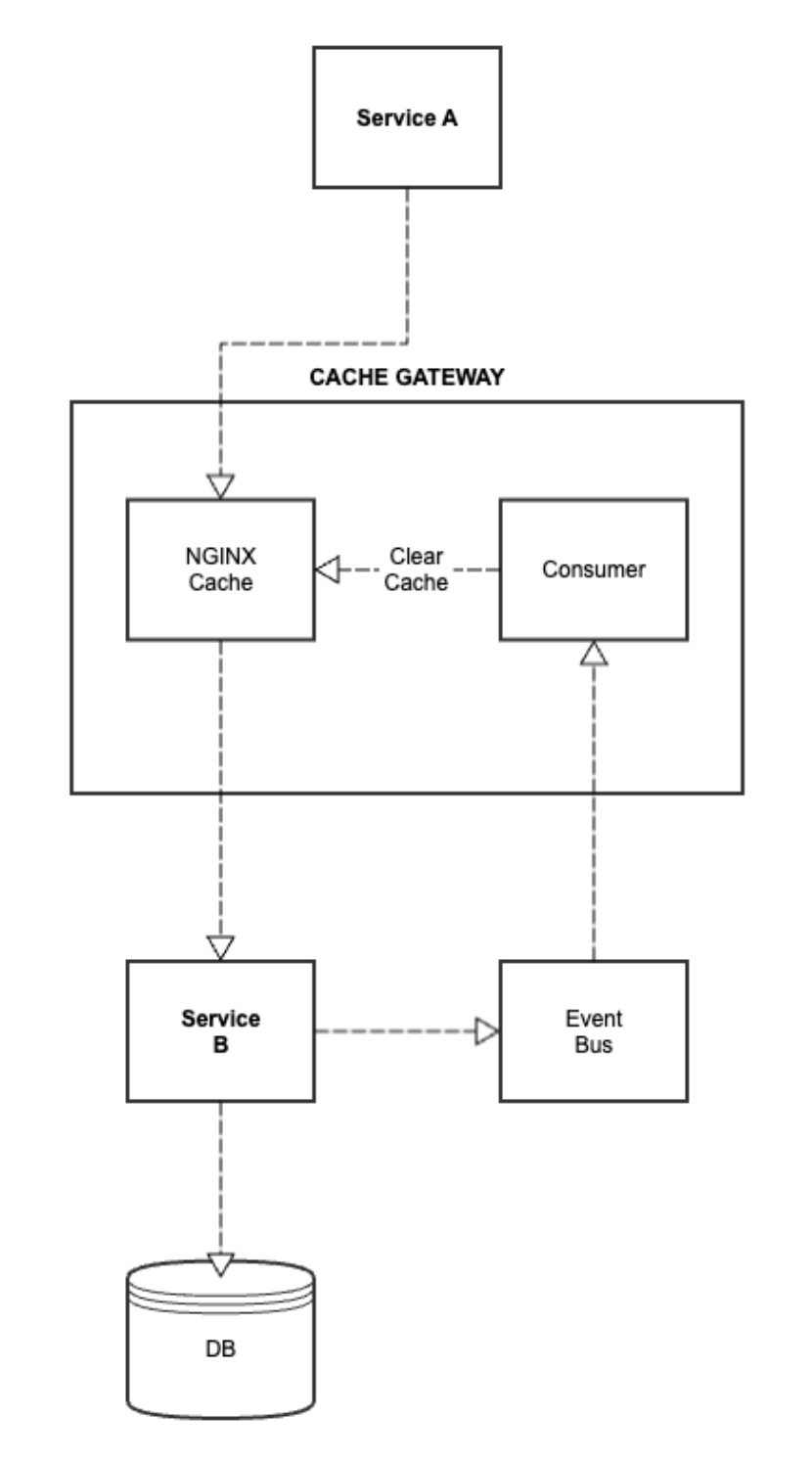
Monitoring Patterns for Proactive Issue Detection
Metric Collection: Monitoring tools collect and record metrics such as CPU usage, memory utilization, network traffic, and response times. These metrics help administrators understand the current state of the system and identify performance bottlenecks or potential issues.
Log Monitoring: Monitoring tools also track logs generated by various components and services within the system. These logs provide valuable information for troubleshooting, auditing, and identifying security incidents.
Resource Monitoring: Monitoring the availability and utilization of system resources, such as disk space, database connections, or server instances, helps ensure optimal resource allocation and avoid resource exhaustion.
Logging Patterns for Troubleshooting and Debugging
Event Logging: Applications and services generate logs to record significant events, errors, warnings, or informational messages. These logs capture essential information for identifying issues, tracking user activities, and troubleshooting problems.
Structured Logging: Using a structured logging approach, where logs are formatted in a standardized and machine-readable manner, enables easier analysis and filtering. Structured logs typically include relevant metadata, timestamps, severity levels, and contextual information.
Log Aggregation: Collecting logs from different sources into a centralized logging system allows for centralized storage, analysis, and searching. This aggregation simplifies log management, enhances log retention, and enables comprehensive analysis across multiple systems or components.
Alerting Pattern for Anomaly Detection
Threshold Monitoring: Setting thresholds on various metrics or conditions allows for real-time monitoring. When a metric breaches a predefined threshold, an alert is triggered to notify the appropriate personnel. For example, a high CPU usage alert can indicate a potential performance issue.
Anomaly Detection: Advanced monitoring systems leverage machine learning algorithms or statistical techniques to identify abnormal patterns or deviations from expected behavior. Anomalies can be indicative of security breaches, performance degradation, or other irregularities.
Notification Channels: Alerts can be delivered through various channels such as email, SMS, chat applications, or integrated with incident management systems. This ensures that relevant stakeholders are promptly informed and can take appropriate actions.
Resiliency Patterns for each challenge
Failures and Errors: Fallback pattern, Retry pattern, Circuit Breaker pattern.
Resource Limitations: Bulkhead pattern.
Network Issues: Retry pattern, Circuit Breaker pattern.
Service Degradation: Circuit Breaker pattern, Fallback pattern.
Scalability and Load Handling: Bulkhead pattern.
System Recovery: Circuit Breaker pattern.
Distributed System Challenges: Replication pattern, Circuit Breaker pattern.
Implementation and benefits
Implementing resiliency patterns in systems can have numerous advantages. Some of the key benefits include:
Enhanced Reliability: Systems become more robust, capable of handling failures without affecting the user experience.
Improved Performance: Optimized resource utilization reduces bottlenecks and ensures better system performance under high demand.
Faster Recovery: Systems can quickly recover and restore stability, minimizing downtime and service disruptions.
Scalability: Resiliency patterns enable effective scaling and handling of increased loads without compromising performance.
Taking Action: Building Resilient Software Systems
Building resilient systems is vital in delivering high-quality products and providing a seamless user experience.
By implementing resiliency patterns, we can address common challenges, improve system stability, and ensure reliable services.
Adopting these patterns improves the resilience of the system and ensures success, even when unexpected events occur.
Assessment and Analysis
Evaluate existing systems, identify improvement areas, and determine relevant resiliency patterns.
Design and Planning
Incorporate resiliency patterns in future designs, considering system-specific challenges. Collaborate with the team for shared understanding.
Implementation and Testing
Implement selected patterns, follow best practices, and test under failure scenarios for refinement.
Monitoring and Maintenance
Establish robust monitoring, track system health, and adjust patterns based on logs and metrics.
Education and Training
Educate teams on resiliency's importance and selected patterns through workshops and knowledge sharing.
Documentation and Knowledge Sharing
Document patterns, purpose, and configuration details. Create a centralized repository for collaboration.
Continuous Improvement
Create an environment that encourages continuous improvement, stay informed about current trends, and actively solicit feedback to make further improvements.